Book review of "Physics of the Future: How Science Will Shape Human Destiny and Our Daily Lives by the Year 2100" by +Michio Kaku.
This was a fun book, but I believe that he is wildly overly pessimistic with regard to his predictions concerning strong AI.
He proposed six "roadblocks to the singularity" which I would like to respond to in turn. He writes:
“No one knows when robots may become as smart as humans. But personally, I would put the date close to the end of the century for several reasons."
“First, the dazzling advances in computer technology have been due to Moore’s law. These advances will begin to slow down and might even stop around 2020-2025, so it is not clear if we can reliably calculate the speed of computers beyond that…"
I believe that there are three reasons that this is incorrect:
1. We don't know if the new paradigms that could replace Moore's law will allow faster or slower continued growth, so things could get better not worse... depending.
2. Parallel computing could allow increased performance even if there is no immediate successor to Moore's law. For example, power consumption / flop continues to drop exponentially

(https://picasaweb.google.com/jlcarroll/Economy#5613003695780064354), and the Brain is a proof by example that it can get down to around 20 wats/10^19 cps... If that trend alone continues, then super computers will continue to increase in performance, even if Moore's Law comes to a screeching halt

3. If you look at my graph, super computers will achieve 10^19cps (the upper bound of the computing power of the brain) just after his 2020 deadline, so it will be too late for the end of Moore's law to stop the creation of strong AI
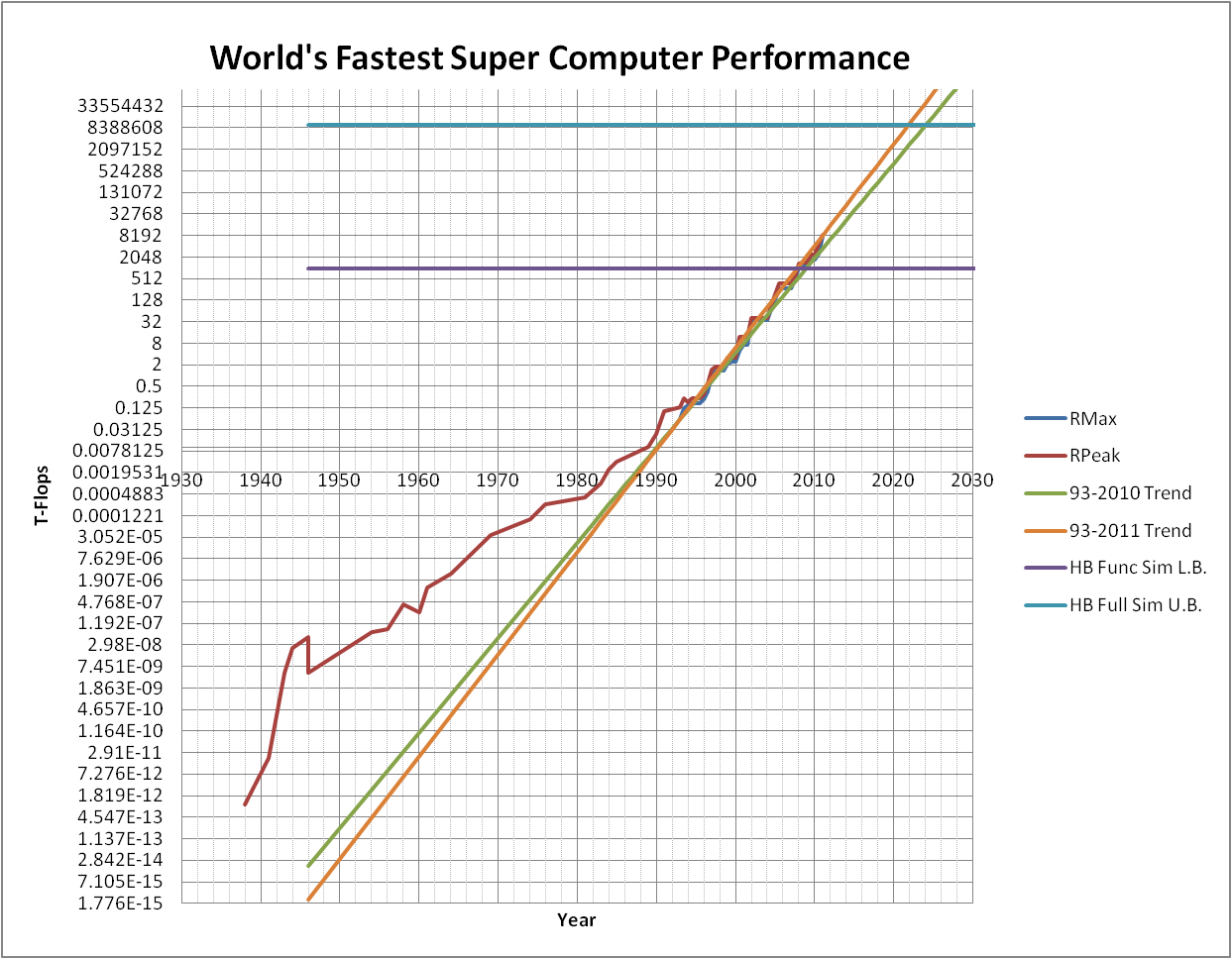
(https://picasaweb.google.com/jlcarroll/Economy#5620432299391054642).
“Second, even if a computer can calculate at fantastic speeds like 10^16 calculations per second, this does not necessarily mean that it is smarter than us…
“Even if computers begin to match the computing speed of the brain, they will still lack the necessary software and programming to make everything work. Matching the computing speed of the brain is just the humble beginning.
To which I respond: That is strictly true, but if we have enough calculations for one computer to simulate the other computer (in this case the human brain), then that computer will indeed be as "intelligent" as the other. The only question is whether such a simulation will be possible, and if so, when it will be possible... more on that later.
“Third, even if intelligent robots are possible, it is not clear if a robot can make a copy of itself that is smarter than the original.…John von Neumann…pioneered the question of determining the minimum number of assumptions before a machine could create a copy of itself. However, he never addressed the question of whether a robot can make a copy of itself that is smarter than it…
“Certainly , a robot might be able to create a copy of itself with more memory and processing ability by simply upgrading and adding more chips. But does this mean the copy is smarter, or just faster…"
It can be trivially shown that a computer/robot can indeed create a new computer/program/robot that is smarter than itself. The fact that Neumann didn't do it doesn't make it any less trivial. How do you do it?
Let's start with human examples, then discuss hardware improvements (assuming that there are no software improvements beyond the brain simulation algorithm), and finally we will discuss whether a computer can make software improvements to its own algorithm.
Humans easily create programs that are "smarter" than the programmer. For example, it is possible for me to easily write a checkers program that plays checkers better than I do. So if you consider intelligence as a multi-dimensional thing, it is clearly possible for an agent to create a new algorithm that is smarter in one or more dimensions of intelligence than itself, with a proof by example (I do it all the time).
Next, hardware improvements:
Michio Kaku admits that a robot can create a copy of itself with more memory and processing ability, but he doubts that such a computer should be called "more intelligent." However, if the robot built a copy of itself with twice the parallel processing power, and if that computer was intelligent by running a simulation of the brain, then it would indeed be more intelligent than before. Why? simple. It can now simulate two brains at the same time, or it can simulate one brain twice as fast (getting twice as much work done on a problem per thinking time spent). No one doubts that two people collaborating on a problem do a better job than one, or that one person who spends twice as much time on a problem gets more done on it.
This can happen because we are simulating the brain with chips that run at about 10^-9 sec, while the human brain fires each neuron at 10^-3 seconds. That means that at first, each processor will be simulating multiple neurons. If you then have twice as many processors, you get to have each chip simulate less neurons, and voila, you can now speed up the simulation considerably, or run multiple simulations at the same time. This doesn't scale up perfectly, nor does it scale up forever, but it will work for quite a while, until we hit limits around where we have one processor for each neuron or synapse (depending), each one running at 10^-9 seconds, and then you may hit something of an impenetrable wall to making the simulation of a single brain go faster. But that still gives us about 10^6 levels of improvement beyond human level intelligence before we hit that wall. Furthermore, after that wall you can still simulate more brains and have them collaborate, each one working on a different part of the problem. That type of scaling should continue roughly forever. Unfortunately twenty people are not always twice as good at solving a problem than ten, so this type of improvement may eventually create diminishing returns. Yet after that limit is reached, it would be possible to put each brain simulation to work on a completely different problem, essentially doing two different things at once. The exact limits to this type of scaling appear to be a very long way off, and all of this assumes that somewhere along the way, we won't find a faster way to do what the brain does, or find a better means of allowing separate minds to collaborate and cooperate in parallel.
It seems to me that we must admit that an AI brain simulation that can do nothing more than add processors to itself is indeed "more intelligent" by any reasonable description of the term.
Now for the issue of software improvements:
Can a simple software program make a copy of itself that is "smarter" than itself? It is trivial to show that this is true. ALL machine learning algorithms are algorithms that "improve" on themselves over time. If they copied their state at one point in time, and then copied their state at a later point in time, then they just created a copy of themselves that where smarter than their previous incarnation.
But it gets better than this. It is possible to work on a meta learning algorithm that "learns to learn", meaning that the AI isn't just better at each problem because it has incorporated more data, but it becomes better at the fundamental problem of how to incorporate data over time. Or it is possible to use the computer to create a genetic algorithm that improves its own algorithms etc. There are thousands of ways in which it is possible for one piece of software to create another that is "smarter than itself." Studying this issue is an entire sub-field of machine learning that goes under the title "Meta-Learning" and "Transfer Learning" and "Learning to Learn". My master's thesis was on this issue and it is unfortunate that Michio Kaku appears to be completely ignorant of this entire field, or he would not have raised such a silly concern. (In his defense, he is a physicist not a computer scientist, however, if he is going to write about someone else's field, he could have at least consulted someone in that field that could have explained to him that he was not making any sense).
“...fourth, although hardware may progress exponentially, software may not…
“Engineering progress often grows exponentially… [but] if we look at the history of basic research, from Newton to Einstein to the present day, we see that punctuated equilibrium more accurately describes the way in which progress is made."
The data seem to indicate that this is not true. If anything, software performance and complexity is growing faster than hardware performance (see http://bits.blogs.nytimes.com/2011/03/07/software-progress-beats-moores-law/).
Furthermore, although I will grant him the idea of punctuated equilibrium, if you step back and view the trends from a distance, it often becomes clear that punctuated equilibrium is nothing more than the steps on a larger exponential trend. Most importantly, software builds on software. Each programming language from machine language, to assembly language, to a compiler, to modern interpreters, to complex and re-usable object libraries, to the current work being done by some of my colleges on statistical programming languages, provide abstractions hiding the complexities of the lower levels from those programming at the upper levels. This trend appears to be continuing, and it is this "building" effect that produces exponential progress.
“Fifth, … the research for reverse engineering the brain, the staggering cost and sheer size of the project will probably delay it into the middle of this century. And then making sense of all this data may take many more decades, pushing the final reverse engineering of the brain to late in this century."
Yes, it will be complex, and yes, it will be expensive (his two central complaints). But he admits elsewhere in his book that it could clearly be done quite rapidly, the only roadblock being the money it would cost. He then makes the absurd claim that there is less perceived "benefit" to be derived from such a simulation, so people won't invest the capital needed to create that simulation. I believe that this is short-sighted. There are many commercial applications for each step along the road to this simulation, and they will only grow as we get closer (see http://www.youtube.com/watch?v=_rPH1Abuu9M). In fact, I believe that there are more potential economic benefits for this work than perhaps for any other in human history. Surely someone else besides me will see the potential, and the funding will flow.
There are many projects working on completing this monumental task, and several are proposing a time line involving around 12 years (incidentally, that is about when my projection of super computer power crosses the upper bound for running this simulation). See: http://www.dailymail.co.uk/sciencetech/article-1387537/Team-Frankenstein-launch-bid-build-human-brain-decade.html#ixzz1Rp7JEF4R and http://www.youtube.com/watch?v=_rPH1Abuu9M.
Our tools for this task are improving exponentially. Our computer power needed to perform this simulation is growing exponentially, our brain scan resolution is growing exponentially http://www.singularity.com/charts/page159.html as is the time resolution of these scans http://www.singularity.com/charts/page160.html.
He does raise another concern related to this one, which I should address:
“Back in 1986, scientists were able to map completely the location of all the nervous system of the tiny worm C. elegans. This was initially heralded as a breakthrough that would allow us to decode the mystery of the brain. But knowing the precise location of its 302 nerve cells and 6,000 chemical synapses did not produce any new understanding of how this worm functions, even decades later. In the same way, it will take many decades, even after the human brain is finally reverse engineered, to understand how all the parts work and fit together. If the human brain is finally reverse engineered and completely decoded by the end of the century, then we will have taken a giant step in creating humanlike robots.” (Michio Kaku “Physics of the Future, How Science will Shape Human Destiny and our Daily Lives by the year 2100” p. 94-95).
We already mapped the brain connections of several very simple animals, but are currently unable to turn this map into an intelligent working simulation. So it would appear that our hardware creates the potential for brain simulation long before our software catches up and is actually capable of performing the simulation. This is the root of his concern.
However, there are a finite number of types of nerve cells, and hormonal interactions that take place in the brain. Once we understand their behavior better, and once we create the algorithm for simulating them, after that moment, it is only a matter of scale and creating the larger more complex neural map. In other words, there is a gap between simulating individual neural behavior and mapping neural connections. Apparently, we can not yet simulate a single neuron's interactions appropriately, and so, knowing the network of connections for these neurons in C elegans is not as helpful as it at first might sound. We will not be able to truly simulate the worm's brain until we solve this problem, and we will not be able to truly simulate the human brain until we solve this problem. But once we can simulate these finite types of neurons correctly, we will be able to accurately simulate the worm's brain, and the human brain as well, once a neural map is created, (and once our computers become sufficiently powerful).
It is my opinion that we will solve this individual neural simulation problem long before we will fully map the human brain. I believe that will take much longer. Why do I believe that we will be able to crack the behavior of neurons so soon? Because first, the complexity of this algorithm is limited by the human genome and its associated expression mechanisms, and second, current progress in this area is quite promising, and it appears that we are currently quite close.
I actually believe that simulating the brain is a much harder problem that do extreme optimists such as Ray Kurzweil who thinks we will be doing this sort of simulation around 2019 (based on the idea that the functional simulation is less complex than the full simulation, which we won't be able to do until 2023 at the earliest). On the other hand, I believe that we will need to do the full simulation first, and then explore that for quite some time before we understand how it is working. But that only pushes things back to 2050 at the latest. Michio Kaku's assertion that 2100 will come, and go, and strong AI will still be years away seems a bit silly to me.
Michio Kaku's sixth and final argument against the singularity is:
“Sixth, there probably won’t be a ‘big bang,’ when machines suddenly become conscious…there is a spectrum of consciousness. Machines will slowly climb up this scale.”
This isn't really a roadblock to the singularity. Every Singularitarian that I know agrees with this. None of them believe that some magic moment will hit and everything will change. They believe that change will accelerate until you won't be able to keep up without merging with our technology and transcending our biology, so this "roadblock" is inaccurately named, and rather irrelevant.



